| Stage | Improvement Percentage |
| A | 46.1 |
| B | 30.0 |
| C | 17.9 |
| D | 7.4 |
| E | 5.5 |
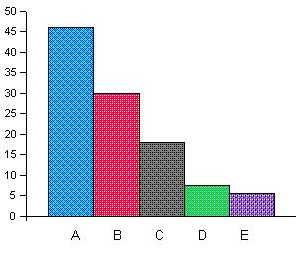
The drop of the improvement percentage over the years
"In precise terms, we ask two questions:
|
| "To answer the second question, in Section 7 we examine a very large number of minor variations on WRR's experiment…" |
| "Our method is to study variations on WRR's experiment. We consider many choices made by WRR when they did their experiment, most of them seemingly arbitrary… and see how often these decisions turned out to be favorable to WRR." (Pg. 158) |
| "…the apparent tuning of one experimental parameter may in
fact be a side-effect of the active tuning of another parameter or parameters. For example, the sets of available appellations performing well for two different proximity measures A and B will not generally be the same. Suppose we adopt measure A and select only appellations optimal for that measure. It is likely that some of the appellations thus chosen will be less good for measure B, so if we now hold the appellations fixed and change the measure from A to B we can expect the result to get weaker. A suspicious observer might suggest we tuned the measure by trying both A and B and selecting measure A because it worked best, when in truth we may never have even considered measure B. The point is that a parameter of the experiment might be tuned directly, or may come to be optimized as a side-effect of the tuning of some other parameters." (Pg. 159) |
|
But their prediction has failed. The experimental results
destroy their thesis: Applying the variations to their list in "War
and Peace" worsens the results only in less than half of the variations! |
| In this chapter we will bring evidence indicating that MBBK's results of the "study of variations" are due to "tuning" of its variations. |
| "Regression to the mean? "In virtually all test-retest situations, the bottom group on the first test will on average show some improvement on the second test - and the top group will on average fall back. This is the regression effect." (Freedman, Pisani and Purves, 1978). Variations on WRR's experiments, which constitute retest situations, are a case in point. Does this, then, mean that they should show weaker results? If one adopts WRR's null hypothesis, the answer is "yes". In that case, the very low permutation rank they observed is an extreme point in the true (uniform) distribution, and so variations should raise it more often than not. However, under WRR's (implicit) alternative hypothesis, the low permutation rank is not an outlier but a true reflection of some genuine phenomenon. In that case, there is no a priori reason to expect the variations to raise the permutation rank more often than it lowers it. (Pg. 159, emphasis ours) |
| "there is no a priori reason to expect the variations to raise the permutation rank more often than it lowers it". |
| "This is especially obvious if the variation holds fixed those aspects of the experiment which are alleged to contain the phenomenon (the text of Genesis, the concept underlying the list of word pairs and the informal notion of ELS proximity)." |
| "As a qualitative exploration of the set of "reasonable experiments" , we examined experiments which are "close by" in the sense that they differ from the original only in some simple way. The classification of these similar experiments as more or less reasonable than the original is highly subjective".(Emphasis ours) |
At any rate we now have two explicit facts derived from MBBK's own words:
|
| "First of all, whatever you do, you've got to say BEFOREHAND "
I'm going to do this and that and that." You've got to do that BEFORE you actually compute anything. And, you've got to give PRECISE criteria for success and failure. YOU can make them up as you wish, but you've got to tell the world BEFOREHAND what they are. And success or failure, you've got to tell us afterward how your tests came out. So we can keep score. That's what they did. I didn't believe they would, but they did. And if you want to convince ME, you're going to have to do the same. If at first you don't succeed, you can keep trying. Just tell us BEFOREHAND what you're doing, and what the criteria are, and whether or not this test is going to be definitive, and so on. You can keep it open, or close it, or do what you want. Just tell us. Beforehand." |
| "Our selection of variations was in all cases as objective as we could manage; we did not select variations according to how they behaved". |
| "For these reasons… we are not going to attempt a quantitative assessment of our evidence. We merely state our case that the evidence is strong and leave it for the reader to judge." (Pg. 159) |
| "Specifically, the Mann-Whitney Sum of Rank statistic comparing the two populations gives a score of 6.42, indicating that the probability of the two sets of variations coming from the same underlying distribution is 6.8E-11." |
| "Mann – Whitney: Column 1: 6.31 sigma, p=1.4E-10. Column 2: 6.97 sigma, p=1.6E-12. Column 3: 6.42 sigma, p=6.8E-11. Column 4: 6.95 sigma, p=1.8E-12. All 4 columns together: 12.88 sigma, p=2.9E-38." |
| "However, since almost all the variations we try amount to only small changes in WRR's experiment, we can expect the following property to hold almost always: if changing each of two parameters makes the result worse, changing them both together also makes the result worse." |
|
To present the facts as if there are 2 x 68 negative results is a
serious deception which calls into question all the variations.
|
|
Let us spare MBBK the embarrassment and remove this data. At least the
33 added variations of the first power should not be included
in "the study of variations". |
| "Our study is based on the following two ideas: a. We focus our attention on ELS with minimal skips. b. We use a two-dimensional arrangement of the text of the Book of Genesis" . (Pg. 5) |
| "In Genesis, though, the phenomenon persists when one confines attention to the more "noteworthy" ELS's, that is, those in which the skip |d| is minimal over the whole text or over large parts of it." (Pg. 430) |
| "This is especially obvious if the variation holds fixed those aspects of the experiment which are alleged to contain the phenomenon (the text of Genesis, the concept underlying the list of word pairs and the informal notion of ELS proximity)." (Pg. 159) |
| "We stress that our definition of distance is not unique. Although there are certain general principles (like minimizing the skip d) some of the details can be carried out in other ways. We feel that varying these details is unlikely to affect the results substantially". (Pg. 431, emphasis ours) |
| "…a simple experiment which to some extent is independent of the original experiment. We did the same computation restricted to those ELS pairs which lie within the cut-off at parameter 20 but no within the cut-off at parameter 10." (emphasis ours) |
| "One appellation (out of 102) is so influential that it contributes a factor of 10 to the result by itself." (pg. 155) |
| L1 | L2 | |||
| Cut-off defining P1 | P2 | Min(r1-r4) | P4 | Min(r1-r4) |
| 0.05 | 1 | 1.0 | 1 | 1.0 |
| 0.1 | 1 | 1.0 | 1 | 1.0 |
| 0.15 | 1 | 1.0 | 1 | 1.0 |
| 0.2 (WRR) | 1 | 1 | 1 | 1 |
| 0.25 | 1 | 0.8 | 1 | 1.0 |
| 0.33 | 1 | 1.0 | 1 | 1.0 |
| 0.4 | 1 | 1.0 | 1 | 1.0 |
| 0.5 | 1 | 0.4 | 1 | 1.0 |
| Cut-off defining P1 | P1 | r1 | P3 | r3 |
| 0.05 | 475487 | 18.76 | 134 | 4.02 |
| 0.1 | 386357 | 84.42 | 1205 | 37.3 |
| 0.15 | 2639 | 26.13 | 74 | 6.43 |
| 0.2 (WRR) | 1 | 1 | 1 | 1 |
| 0.25 | 0.0024 | 0.069 | 0.019 | 0.13 |
| 0.33 | 0.0008 | 0.098 | 2.47 | 6.12 |
| 0.4 | 0.001 | 0.19 | 0.63 | 4.03 |
| 0.5 | 0.00013 | 0.036 | 0.018 | 0.41 |
| Cut-off defining P1 | P1 | r1 | P3 | r3 |
| 0.05 | 105048 | 18.5 | 5157 | 8.04 |
| 0.1 | 133 | 1.89 | 6.57 | 0.26 |
| 0.15 | 145 | 4.0 | 14.4 | 1.26 |
| 0.2 (WRR) | 1 | 1 | 1 | 1 |
| 0.25 | 0.00032 | 0.014 | 0.000015 | 0.0019 |
| 0.33 | 0.00034 | 0.05 | 0.0001 | 0.018 |
| 0.4 | 0.0083 | 0.21 | 0.0048 | 0.14 |
| 0.5 | 0.055 | 0.9 | 0.05 | 1.0 |
| Cut-off defining P1 | Min(P1-P2) | |
| L1 | L2 | |
| 0.05 | 1.32 | 1.0 |
| 0.1 | 1.32 | 1.0 |
| 0.15 | 1.32 | 1.0 |
| 0.2 (WRR) | 1 | 1 |
| 0.25 | 0.0024 | 0.007 |
| 0.33 | 0.0008 | 0.0074 |
| 0.4 | 0.001 | 0.18 |
| 0.5 | 0.00013 | 1.0 |
| "Values greater than 0.2 have a dramatic effect on P1, reducing it by a large factor (especially for the first list). However, the result of the permutation test on P1 does not improve so much, and for the second list it is never better than that for P4," (Pg. 171) |
| "Wonder of wonders, however, it turns out that almost always (though not quite always) the allegedly blind choices paid off: Just about anything that could have been done differently from how it was actually done would have been detrimental to the list's ranking in the race". |
| A1 | A2 | |
| better | 12 | 11 |
| equal | 18 | 14 |
| worse | 44 | 63 |
| total | 74 | 88 |
| Sample | L1 | L2 | ||
| Statistic | P2 | Min(r1-r4) | P4 | Min(r1-r4) |
| e(A1) | 0.733 | 0.400 | 0.706 | 0.591 |
| e(A2) | 0.682 | 0.667 | 0.750 | 0.773 |
| Variation | L1 | L2 | ||
| P2 | Min(r1-r4) | P4 | Min(r1-r4) | |
| Use 1 value of i | 2e5 | 340 | 31 | 21 |
| or 2 | 2e4 | 210 | 3.4 | 4.5 |
| or 5 | 3.7 | 0.6 | 0.3 | 0.2 |
| or 10 (WRR) | 1 | 1 | 1 | 1 |
| or 15 | 3.6 | 3.3 | 1.4 | 1.1 |
| or 20 | 11.8 | 5.9 | 3.1 | 3.8 |
| or 25 | 66 | 15.3 | 4.8 | 5.4 |
| or 50 | 3600 | 40 | 93 | 28 |
| Variation | L1 | L2 | ||
| P2 | Min(r1-r4) | P4 | Min(r1-r4) | |
| i=5 | 3.7 | 0.6 | 0.3 | 0.2 |
| i=6 | 2.1 | 0.5 | 0.5 | 0.5 |
| i=7 | 3.4 | 2.5 | 0.3 | 0.3 |
| i=8 | 2.7 | 1.7 | 0.2 | 0.2 |
| i=9 | 0.7 | 0.7 | 0.4 | 0.5 |
| or 10 (WRR) | 1 | 1 | 1 | 1 |
| i=11 | 0.8 | 0.9 | 0.6 | 0.7 |
| i=12 | 1.1 | 1.2 | 0.8 | 0.8 |
| i=13 | 1.3 | 1.3 | 1.2 | 1.0 |
| i=14 | 1.8 | 2.0 | 1.1 | 0.9 |
| i=15 | 3.6 | 3.3 | 1.4 | 1.4 |
| Variation | L1 | L2 | ||
| P2 | Min(r1-r4) | P4 | Min(r1-r4) | |
| i=3 | 2053 | 91 | 1.1 | 1.8 |
| i=4 | 119 | 16.4 | 0.1 | 0.2 |
| Variation | L1 | L2 | ||
| P2 | Min(r1-r4) | P4 | Min(r1-r4) | |
| Expected ELS count of 2 | 7600 | 7.0 | 4e4 | 310 |
| or 5 | 53 | 53 | 20 | 19.5 |
| or 10 (WRR) | 1 | 1 | 1 | 1 |
| or 15 | 1.2 | 2.9 | 5.9 | 2.0 |
| or 20 | 2.7 | 8.3 | 59 | 7.1 |
| or 25 | 0.8 | 4.0 | 91 | 15.2 |
| or 30 | 6.8 | 14.1 | 140 | 22 |
| or 50 | 2.2 | 4.1 | 550 | 79 |
| or 75 | 3.7 | 4.5 | 590 | 81 |
| or 100 | 4.0 | 4.7 | 560 | 62 |
| Variation | L1 | L2 | ||
| P2 | Min(r1-r4) | P4 | Min(r1-r4) | |
| Expected ELS count of 5 | 53 | 1.6 | 20 | 19.5 |
| Or 6 | 6.3 | 0.8 | 3.8 | 0.9 |
| Or 7 | 204 | 8.8 | 0.4 | 0.5 |
| Or 8 | 6.2 | 2.4 | 2.0 | 0.8 |
| Or 9 | 9.0 | 4.1 | 1.6 | 1.0 |
| Or 10 (WRR) | 1 | 1 | 1 | 1 |
| Or 11 | 1.3 | 1.3 | 1.9 | 1.8 |
| Or 12 | 4.7 | 3.6 | 1.3 | 0.7 |
| Or 13 | 2.4 | 2.5 | 4.2 | 0.9 |
| Or 14 | 3.0 | 3.0 | 3.6 | 0.9 |
| Or 15 | 1.2 | 2.9 | 5.9 | 2.0 |
| L1 | L2 | |||
| Cut-off defining P1 | P2 | Min(r1-r4) | P4 | Min(r1-r4) |
| 0.05 | 1 | 1.0 | 1 | 1.0 |
| 0.1 | 1 | 1.0 | 1 | 1.0 |
| 0.15 | 1 | 1.0 | 1 | 1.0 |
| 0.2 (WRR) | 1 | 1 | 1 | 1 |
| 0.25 | 1 | 0.8 | 1 | 1.0 |
| 0.33 | 1 | 1.0 | 1 | 1.0 |
| 0.4 | 1 | 1.0 | 1 | 1.0 |
| 0.5 | 1 | 0.4 | 1 | 1.0 |
| L1 | L2 | |||
| Cut-off defining P1 | P2 | Min(r1-r4) | P4 | Min(r1-r4) |
| 0.05 | 1 | 1.0 | 1 | 1.0 |
| 0.1 | 1 | 1.0 | 1 | 1.0 |
| 0.15 | 1 | 1.0 | 1 | 1.0 |
| 0.2 (WRR) | 1 | 1 | 1 | 1 |
| 0.25 | 1 | 0.8 | 1 | 1.0 |
| 0.3 | 1 | 0.3 | 1 | 1.0 |
| 0.35 | 1 | 0.3 | 1 | 1.0 |
| 0.4 | 1 | 1.0 | 1 | 1.0 |
| 0.45 | 1 | 1.0 | 1 | 1.0 |
| 0.5 | 1 | 0.4 | 1 | 1.0 |
| Variation | L1 | L2 | ||
| Denominator bound | P2 | Min(r1-r4) | P4 | Min(r1-r4) |
| 2 | 2.9 | 1.0 | 1.0 | 1.0 |
| 3 | 2.9 | 1.2 | 1.0 | 1.0 |
| 4 | 1.8 | 1.2 | 1.0 | 1.0 |
| 5 | 1.8 | 1.2 | 1.0 | 1.0 |
| 10 (WRR) | 1 | 1 | 1 | 1 |
| 15 | 1.0 | 1.0 | 1.0 | 1.0 |
| 20 | 1.0 | 0.9 | 1.1 | 1.1 |
| 25 | 1.0 | 1.0 | 1.1 | 1.1 |
| Variation | L1 | L2 | ||
| P2 | Min(r1-r4) | P4 | Min(r1-r4) | |
| Perturb up to 3 places | 0.2 | 2.4 | 0.04 | 1.1 |
| or 4 places | 0.2 | 4.2 | 0.005 | 0.6 |
| Perturb last 2 places | 5e4 | 4.5 | 6700 | 38 |
| up to 3 places | 118 | 2.4 | 340 | 18.6 |
| or 4 places | 2.5 | 0.6 | 135 | 48 |
| Variation | L1 | L2 | ||
| P2 | Min(r1-r4) | P4 | Min(r1-r4) | |
| Perturb up to 3 places | 0.2 | 2.4 | 0.04 | 1.1 |
| or 4 places | 0.2 | 4.2 | 0.005 | 0.6 |
| or 5 places | 0.1 | 5.0 | 0.0007 | 0.3 |
| or 6 places | 0.07 | 4.8 | 0.0003 | 0.3 |
| Variation | L1 | L2 | ||
| P2 | Min(r1-r4) | P4 | Min(r1-r4) | |
| Minimum row length of 3 | 0.9 | 1.0 | 1.3 | 1.2 |
| or 4 | 0.9 | 1.0 | 1.0 | 1.1 |
| or 5 | 0.9 | 1.0 | 1.2 | 1.3 |
| or 10 | 1.1 | 0.9 | 5.4 | 5.9 |
| Variation | L1 | L2 | ||
| P2 | Min(r1-r4) | P4 | Min(r1-r4) | |
| Minimum skip of 1 | 1.5 | 2.1 | 0.1 | 5.0 |
| or 3 | 0.3 | 0.7 | 11.1 | 5.9 |
| or 4 | 1.2 | 1.6 | 16.3 | 7.9 |
| or 5 | 0.5 | 0.8 | 16.7 | 11.3 |
| or 10 | 13.7 | 0.6 | 33 | 35 |
| The fact that sample points were added later, and especially where the results could be foreseen, raises the question: In how many stages was the data sampled in the original report of McKay?! |
| "Our selection of variations was in all cases as objective as we could manage; we did not select variations according to how they behaved". (Pg. 161) |
| L1 | L2 | |||||
| P1 | P2 | Min(P1-P2) | P1 | P2 | Min(P1-P2) | |
| better | 35 | 13 | 38 | 35 | 38 | 42 |
| equal | 10 | 3 | 10 | 21 | 6 | 10 |
| worse | 57 | 79 | 54 | 46 | 51 | 50 |
| not worse | 45 | 16 | 48 | 56 | 44 | 52 |
| total | 102 | 95 | 102 | 102 | 95 | 102 |
| P1 | P2 | P3 | P4 | Min(P1-P4) | Min(P1-P2) | |
| better | 35 | 13 | 18 | 17 | 38 | 38 |
| equal | 10 | 3 | 21 | 7 | 10 | 10 |
| worse | 57 | 79 | 63 | 71 | 54 | 54 |
| not worse | 45 | 16 | 39 | 24 | 48 | 48 |
| total | 102 | 95 | 102 | 95 | 102 | 102 |
| P1 | P2 | P3 | P4 | Min(P1-P4) | Min(P1-P2) | |
| better | 35 | 38 | 52 | 31 | 42 | 42 |
| equal | 21 | 6 | 14 | 7 | 10 | 10 |
| worse | 46 | 51 | 36 | 57 | 50 | 50 |
| not worse | 56 | 44 | 66 | 38 | 52 | 52 |
| total | 102 | 95 | 102 | 95 | 102 | 102 |
| r1 | r2 | r3 | r4 | Min(r1-r4) | Min(r1-r2) | |
| better | 31 | 8 | 27 | 6 | 13 | 13 |
| equal | 10 | 10 | 6 | 14 | 14 | 14 |
| worse | 61 | 77 | 69 | 75 | 75 | 75 |
| not worse | 41 | 18 | 33 | 20 | 27 | 27 |
| total | 102 | 95 | 102 | 95 | 102 | 102 |
| r1 | r2 | r3 | r4 | Min(r1-r4) | Min(r1-r2) | |
| better | 32 | 6 | 53 | 4 | 4 | 6 |
| equal | 11 | 7 | 11 | 6 | 13 | 14 |
| worse | 59 | 82 | 38 | 85 | 85 | 82 |
| not worse | 43 | 13 | 64 | 10 | 17 | 20 |
| total | 102 | 95 | 102 | 95 | 102 | 102 |
| This arouses suspicion that the results have no connection to the existence or otherwise of optimization! We will deal with this in Chap. IV. |
| "Conclusions. As can be seen from the Appendices, the results are remarkably consistent: only a small fraction of variations made WRR's result stronger and then usually by only a small amount." (Pg. 161) |
| "What measures should we compare? Another technical problem concerns the comparison of two variations. Should we use the success measures employed by WRR at the time they compiled the data, or those later adopted for publication?" |
| "In the case of the first list, the only overall measures of success used by WRR were P2 and their P1-precursor (see Section 3). The relative behavior of P1 on slightly different metrics depends only on a handful of c(w, w') values close to 0.2, and thus only on a handful of appellations. By contrast, P2 depends continuously on all of the c(w, w') values, so it should make a more sensitive indicator of tuning. Thus, we will use P2 for the first list." |
| "For the second list, P3 is ruled out for the same lack of sensitivity as P1, leaving us to choose between P2 and P4." |
| "Sensitivity to a small part of the data. A worrisome aspect of WRR's method is its reliance on multiplication of small numbers. The values of P2 and P4 are highly sensitive to the values of the few smallest distances, and this problem is exacerbated by the positive correlation between c(w, w') values. Due in part to this property, WRR's result relies heavily on only a small part of their data." (emphasis ours). |
| L1 | L2 | |||
| P1 | P3 | P1 | P3 | |
| better | 35 | 18 | 35 | 52 |
| equal | 10 | 21 | 21 | 14 |
| worse | 57 | 63 | 46 | 36 |
| not worse | 45 | 39 | 56 | 66 |
| total | 102 | 102 | 102 | 102 |
| "These two measures differ only in whether appellations of the form "Rabbi X" are included (P2) or not (P4). However, experimental parameters not subject to choice cannot be involved in tuning, and because the "Rabbi X" appellations were forced on WRR by their prior use in the first list, we can expect P4 to be a more sensitive indicator of tuning than P2. Thus, we will use P4." |
| "In addition to P2 for the first list and P4 for the second, we will show the effect of experiment variations on the least of the permutation ranks of P1-P4. This is not only the sole success measure presented in WRR94, but there are other good reasons. The permutation rank of P4, for example, is a version of P4 which has been "normalized" in a way that makes sense in the case of experimental variations that change the number of distances, or variations that tend to uniformly move distances in the same direction. For this reason, the permutation rank of P4 should often be a more reliable indicator of tuning than P4 itself. The permutation rank also to some extent measures P1-P4 for both the identity permutation and one or more cyclic shifts, so it might tend to capture tuning towards the objectives mentioned in the previous paragraph. (Recall from Section 3 that WRR had been asked to investigate a "randomly chosen" cyclic shift.)" |
| "The permutation rank of P4, for example, is a version of P4 which has been "normalized" in a way that makes sense in the case of experimental variations that change the number of distances, or variations that tend to uniformly move distances in the same direction. For this reason, the permutation rank of P4 should often be a more reliable indicator of tuning than P4 itself." |
| "in the case of experimental variations that change the number of distances". |
| "Furthermore, in all 19 cases where P4 dropped, the permutation rank of P4 increased. This indicates that the observed drop in P4 values is due to an overall tendency for c(w, w') values to decrease when these variations are applied." |
| Furthermore, in all 19 cases where the permutation rank of P4 increased, P4 dropped. This indicates that the observed increase in the values of the permutation rank of P4 is due to an overall tendency for permutation ranks to increase when these variations are applied. |
| "in other words, it is an example of the inadequacy of P4 as an indirect indicator of tuning, as discussed in Section 7," |
| In other words, it is an example of variations being chosen according to their destructive effect on r4, as discussed in Chap. V (of this paper). |
| "The permutation rank also to some extent measures P1_4 for both the identity permutation and one or more cyclic shifts, so it might tend to capture tuning towards the objectives mentioned in the previous paragraph. (Recall from Section 3 that WRR had been asked to investigate a " randomly chosen" cyclic shift.)" |
| "Lest there be a misunderstanding, we hasten to repeat that the fact that a particular choice made by Witztum and Rips turned out to be better than its alternative by no means implies that both were checked and the superior one was chosen. The method whereby War and Peace list is cooked did not involve any of these choices, because they were imposed already. All choices were limited to which names and appellations to include and how to spell them. Nonetheless, our list would have fared similarly to theirs under the same checks. If a list of names is cooked to optimize some statistic given some choices, the choices look as if they were cooked to optimize the statistic given the list of names." (Pg. 19, emphasis ours) |
| r1 | r2 | r3 | r4 | Min(r1-r4) | Min(r1-r2) | |
| better | 57 | 58 | 43 | 52 | 52 | 58 |
| equal | 1 | 4 | 2 | 2 | 9 | 11 |
| worse | 44 | 33 | 57 | 41 | 41 | 33 |
| not worse | 58 | 62 | 45 | 54 | 61 | 69 |
| total | 102 | 95 | 102 | 95 | 102 | 102 |
| P1 | P2 | P3 | P4 | Min(P1-P4) | Min(P1-P2) | |
| better | 55 | 64 | 38 | 59 | 57 | 66 |
| equal | 7 | 5 | 11 | 7 | 6 | 10 |
| worse | 40 | 26 | 53 | 29 | 39 | 26 |
| not worse | 62 | 69 | 49 | 66 | 63 | 76 |
| total | 102 | 95 | 102 | 95 | 102 | 102 |
| P1 | P2 | P3 | P4 | Min(P1-P4) | Min(P1-P2) | |
| better | 5 | 21 | 8 | 17 | 21 | 21 |
| equal | 20 | 8 | 23 | 7 | 15 | 15 |
| worse | 77 | 66 | 71 | 71 | 66 | 66 |
| not worse | 25 | 29 | 31 | 24 | 36 | 36 |
| total | 102 | 95 | 102 | 95 | 102 | 102 |
| r1 | r2 | r3 | r4 | Min(r1-r4) | Min(r1-r2) | |
| better | 17 | 16 | 16 | 17 | 17 | 16 |
| equal | 14 | 10 | 13 | 8 | 15 | 17 |
| worse | 71 | 69 | 73 | 70 | 70 | 69 |
| not worse | 31 | 26 | 29 | 25 | 32 | 33 |
| total | 102 | 95 | 102 | 95 | 102 | 102 |
| P1 | P2 | |
| better | 35 | 50 |
| equal | 14 | 8 |
| worse | 53 | 37 |
| not worse | 49 | 58 |
| total | 102 | 95 |
| r1 | r2 | |
| better | 41 | 45 |
| equal | 9 | 16 |
| worse | 52 | 34 |
| not worse | 50 | 61 |
| total | 102 | 95 |
| P1 | P2 | |
| better | 2 | 39 |
| equal | 21 | 18 |
| worse | 79 | 38 |
| Not worse | 23 | 57 |
| total | 102 | 95 |
| r1 | r2 | |
| better | 8 | 40 |
| equal | 17 | 28 |
| worse | 77 | 27 |
| Not worse | 25 | 68 |
| total | 102 | 95 |
| Sample | Indication of Optimization | No Indication of Optimization |
| L1 | P2, P4, r2, r4, Min(r1-r2), Min(r1-r4). |
P1,P3,Min(P1-P2),Min(P1-P4), r1, r3. |
| L2 | r2, r4, Min(r1-r2), Min(r1-r4). | P1,P2,P3,P4,Min(P1-P2),Min(P1-P4), r1, r3. |
| BM Sample in War & Peace |
None | P1,P2,P3,P4,Min(P1-P2),Min(P1-P4), r1, r2, r3, r4, Min(r1-r2), Min(r1-r4). |
| EM3(1) | P1, P4, r2, r3, r4. |
P2, P3, Min(P1-P2), Min(P1-P4), r1, Min(r1-r2), Min(r1-r4). |
| RABBI1 | None | P1, P2. r1, r2. |
| RABBI2 | P1, r1. |
P2, r2. |
| Sample | Indication of Optimization | No Indication of Optimization |
| L1 | P2, P3, P4, r2,r3,r4, Min(r1-r2), Min(r1-r4). |
P1, Min(P1-P2), Min(P1-P4), r1. |
| L2 | r2, r4, Min(r1-r2), Min(r1-r4). |
P1,P2,P3,P4,Min(P1-P2),Min(P1-P4), r1, r3. |
in War & Peace |
None | P1,P2,P3,P4,Min(P1-P2),Min(P1-P4), r1, r2, r3, r4, Min(r1-r2), Min(r1-r4). |
| EM3(1) | P1,P2,P3,P4,Min(P1-P2),Min(P1-P4), r1, r2, r3, r4, Min(r1-r2), Min(r1-r4). |
None |
| RABBI1 | None | P1, P2. r1, r2. |
| RABBI2 | P1, r1. |
P2, r2. |
| "WRR's first list of rabbis and their appellations and dates appeared in WRR94 too, but no results are given except some histograms of c(w,w') values. Since WRR have consistently maintained that their experiment with the first list was performed just as properly as their experiment with the second list, we will investigate both." (Pg. 154) |
| P1 | P2 | Min(P1-P2) | |
| better | 35 | 38 | 42 |
| equal | 21 | 6 | 10 |
| worse | 46 | 51 | 50 |
| not worse | 56 | 44 | 52 |
| total | 102 | 95 | 102 |
| "We reiterate that out of all the cases we looked at, which by now number in the hundreds, WRR's choices were fortunate uncannily often" . (Pg. 51) |
| "Wonder of wonders, however, it turns out that almost always (though not quite always) the allegedly blind choices paid off: Just about anything that could have been done differently from how it was actually done would have been detrimental to the list's ranking in the race". (pg. 18) |
| P4 | Min(r1-r4) | |
| better | 31 | 4 |
| equal | 7 | 13 |
| worse | 57 | 85 |
| not worse | 38 | 17 |
| total | 95 | 102 |
| "Conclusions. As can be seen from the Appendices, the results are remarkably consistent: only a small fraction of variations made WRR's result stronger and then usually by only a small amount. This trend is most extreme for the permutation test in the second list, the only success measure presented in WRR94." (Pg. 169, emphasis ours) |
|
The drop of the improvement percentage over the years |
| "In the previous sections we discussed some of the choices that were available to WRR when they did their experiment, and showed that the freedom provided just in the selection of appellations is sufficient to explain the strong result in WRR94." (Pg. 157) |
| P3 | P4 | r3 | r4 | |
| better | 52 | 31 | 53 | 4 |
| equal | 14 | 7 | 11 | 6 |
| worse | 36 | 57 | 38 | 85 |
| not worse | 66 | 38 | 64 | 10 |
| total | 102 | 95 | 102 | 95 |
| Dates only as ELSs | Regular calculation | Appellations only as ELSs | |
| better | 26 | 31 | 29 |
| equal | 7 | 7 | 7 |
| worse | 60 | 57 | 57 |
| not worse | 33 | 38 | 36 |
| total | 93 | 95 | 93 |
| Sample | Imp(P4) | Imp(r4) | Q |
| L1 | 17 | 6 | 2.83 |
| L2 | 31 | 4 | 7.75 |
in War & Peace |
|||
| EM3(1) | 17 | 17 | 1.00 |
| RABBI1 | 51 | 45 | 1.13 |
| RABBI2 | 39 | 40 | 0.98 |
| EM3 | A | B | ||||
| P3 | P4 | P3 | P4 | P3 | P4 | |
| better | 9 | 12 | 9 | 16 | 60 | 41 |
| equal | 26 | 11 | 30 | 8 | 16 | 10 |
| worse | 67 | 72 | 63 | 71 | 26 | 44 |
| not worse | 35 | 23 | 39 | 24 | 76 | 51 |
| total | 102 | 95 | 102 | 95 | 102 | 95 |
| EM3 | A | B | ||||
| r3 | r4 | r3 | r4 | r3 | r4 | |
| better | 13 | 14 | 15 | 11 | 72 | 22 |
| equal | 9 | 7 | 13 | 10 | 9 | 10 |
| worse | 80 | 74 | 74 | 74 | 21 | 63 |
| not worse | 22 | 21 | 28 | 21 | 81 | 32 |
| total | 102 | 95 | 102 | 95 | 102 | 95 |
| EM3 | A | B | ||||
| r3 | r4 | r3 | r4 | r3 | r4 | |
| better | 18 | 15 | 17 | 14 | 76 | 37 |
| equal | 9 | 9 | 14 | 8 | 10 | 8 |
| worse | 75 | 71 | 71 | 73 | 16 | 51 |
| not worse | 27 | 24 | 31 | 22 | 86 | 45 |
| total | 102 | 95 | 102 | 95 | 102 | 95 |